Ziyu Wang
I'm a postdoctoral researcher at the Department of Statistics, University of Oxford where I'm working with Chris Holmes. Before this, I received my PhD
in Computer Science from Tsinghua University, where I worked with Jun Zhu and Bo Zhang.
I work in probabilistic machine learning. I'm particularly interested in uncertainty quantification, Bayes-inspired ideas, and learning in out-of-distribution settings.
You can reach me at wzy196 at gmail.com. My CV.
Other persons with the same name.
Publications
-
On Uncertainty Quantification for Near-Bayes Optimal Algorithms.
Ziyu Wang, Chris Holmes.
arXiv preprint. PDF
TL;DR
- Many popular ML prediction algorithms don't have a natural Bayesian analogue, and even when they do it can be hard to implement:
think DNNs, boosting and stacking algorithms, AutoML systems with their hyperparameter tuning magic, or the GPT finetuning service.
As Bayesian people what can we do?
- In this work we start from an arguably more natural alternative: the (point prediction) algorithm of interest is near Bayes-optimal w.r.t. an unknown task distribution π, which models the present task/dataset well.
Then π provides an unknown but ideal Bayesian prior -- Solomonoff's universal prior, if you wish.
- As a few examples: models such as ResNet and ViT are validated on countless applications. Design choices of AutoML systems are often determined based on evaluations on a benchmark suite. Foundation models are pretrained on a diverse mix of datasets.
- In all cases we want to use an algorithm for our present task only because we've seen evidence that it worked well on a large number of similar tasks. If we view these tasks as i.i.d. samples from some π, the algorithm we choose will represent our best attempt towards achieving Bayes optimality w.r.t. π.
-
Having exact knowledge of π would be ideal: the π-posterior would be Bayes optimal.
But in reality we don't exactly know about π;
our base algorithm is only possibly near-Bayes optimal; and unlike exact Bayesian procedures the algorithm may not provide us with a notion of (epistemic) uncertainty at all.
-
But as we show in the paper, it is often possible to recover a good approximation of the unknown posterior through the construction of martingale posteriors.
And far more often we can use the theory-inspired method to mitigate overfitting and quantify predictive uncertainty.
We illustrate our procedure on a variety of base algorithms including Gaussian processes, boosting trees, AutoML algorithms and diffusion models.
-
Are Large Language Models Bayesian? A Martingale Perspective to In-Context Learning.
Fabian Falck*, Ziyu Wang*, Chris Holmes.
To appear in ICML 2024.
Workshop version (SeT LLM @ ICLR)
TL;DR
- No, not if we (following various previous works) interpret this hypothesis as
"LLM-based ICL approximates a Bayesian model for exchangeable observations".
- We derived tests for exchangeability and a weaker c.i.d. condition, which must hold if the hypothesis does.
We also discussed why you should care about these conditions if you don't care about being Bayesian.
- But in some cases the LMs approximate the c.i.d. condition sufficiently well so that we can recover
the scaling of epistemic uncertainty.
-
A Constrained Bayesian Approach to Out-of-Distribution Prediction.
Ziyu Wang*, Binjie Yuan*, Jiaxun Lu, Bowen Ding, Yunfeng Shao, Qibin Wu, Jun Zhu.
UAI 2023. PDF
Code
Poster
TL;DR
- OOD generalization is workable if we have a simple model and many training domains, and less so otherwise. But in practice we can often afford to label a few test samples, and use them to adapt to domain shift.
- In this work we propose a constrained Bayesian approach for this task, which basically constraints the hypothesis space to be "slightly larger" than the solution set in group DRO. In this way we avoid a pitfall of the latter, which occurs we don't have a sufficiently diverse collection of training domains.
- We substantiate the above claim with theoretical analyses and simulations. We also demonstrate, on several datasets including one from a real-world problem, our method outperforms standard domain generalization methods and several heuristics for adaptation.
-
On Equivalences between Weight and Function-Space Langevin Dynamics.
Ziyu Wang, Yuhao Zhou, Ruqi Zhang, Jun Zhu.
ICBINB Workshop @ NeurIPS 2022. PDF
TL;DR
-
Spectral Representation Learning for Conditional Moment Models.
Ziyu Wang, Yucen Luo, Yueru Li, Jun Zhu, Bernhard Schölkopf.
arXiv preprint. PDF
TL;DR
- We studied the estimation of certain high-dimensional NPIV-type problems. Whereas past approaches typically assumed access to hypothesis spaces with a controlled measure of ill-posedness, we showed that such hypothesis spaces can be automatically learned from data, after which a more efficient estimator can be constructed.
- This is based on the observation that it suffices to learn the spectral decomposition of a conditional expectation operator, and contrastive learning fulfills this goal.
-
Fast Instrument Learning with Faster Rates.
Ziyu Wang, Yuhao Zhou, Jun Zhu.
NeurIPS 2022. PDF
Code
Slides
TL;DR
- Sketches the optimal "instrument kernel" used in kernelized IV methods, using adaptive regression algorithms accessed as a black-box.
- The kernel learning formulation eases optimization and enables uncertainty quantification in high dimensions. It also connects to multi-task learning.
-
Quasi-Bayesian Dual Instrumental Variable Regression.
Ziyu Wang*, Yuhao Zhou*, Tongzheng Ren, Jun Zhu.
Short version in NeurIPS 2021. PDF
Full version
Code
MLECON Poster
Slides
TL;DR
- Quasi-Bayesian inference for kernelized and (heuristically) NN-parameterized IV models, based on the dual/minimax formulation of IVR.
- Quasi-Bayes is needed for IV because we can't do Bayesian modeling, which is because we don't know the full data generating process.
- A guess will likely be wrong, and still difficult to make use of, because you will have to do Bayesian inference over deep [conditional] generative models.
- We establish optimal posterior contraction rates in L2 and Sobolev norms, and study frequentist validity of credible balls. These results improve the understanding of both quasi-Bayesian and kernelized IV methods.
- We also present an inference algorithm using a modified randomized prior trick, which enables application to wide NNs.
-
Fork or Fail: Cycle-Consistent Training with Many-to-One Mappings.
Qipeng Guo, Zhijing Jin, Ziyu Wang, Xipeng Qiu, Weinan Zhang, Jun Zhu, Zheng Zhang, David Wipf.
AISTATS 2021.
PDF
TL;DR
- Domain alignment without paired data, when bijections do not exist.
-
Further Analysis of Outlier Detection with Deep Generative Models.
Ziyu Wang, Bin Dai, David Wipf, Jun Zhu.
NeurIPS 2020.
PDF
Code
Poster
Slides
TL;DR
- This is about the observation that DGMs assign higher likelihood to semantically different outliers.
Intuitively this is due to concentration of measure / typicality ("Gaussian distributions are soap bubbles"), but it seemed difficult to confirm empirically.
- We argue previous attempts relied on tests that were more prone to estimation error, and propose a fix which connects to the idea of atypicality and the longitudinal view of high-dimensional data.
- A few other observations are difficult to summarize, so check out the paper if you're interested.
-
The Usual Suspects? Reassessing Blame for VAE Posterior Collapse.
Bin Dai, Ziyu Wang, David Wipf.
ICML 2020.
PDF
TL;DR
- Reasons for posterior collapse in nonlinear VAEs, which may or may not be similar to the linear case.
- Of particular importance is the practicality of designing AE architecture with low reconstruction errors.
-
A Wasserstein Minimum Velocity Approach to Learning Unnormalized Models.
Ziyu Wang, Shuyu Cheng, Yueru Li, Jun Zhu, Bo Zhang.
AISTATS 2020.
PDF
Code
AABI Poster
TL;DR
- An alternative approximation to the score matching objectives, which works with DNNs. And generalizations.
- The title was a tribute to the unpublished work "A Minimum Velocity Approach to Learning".
-
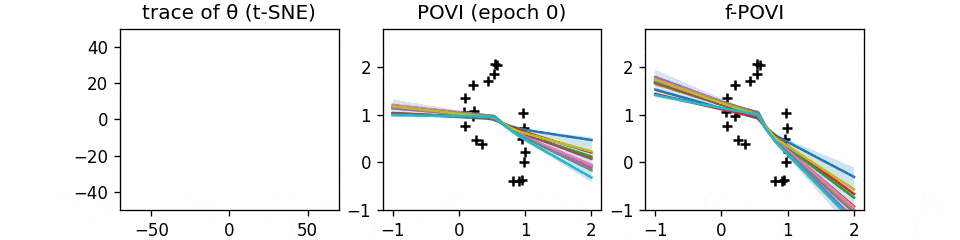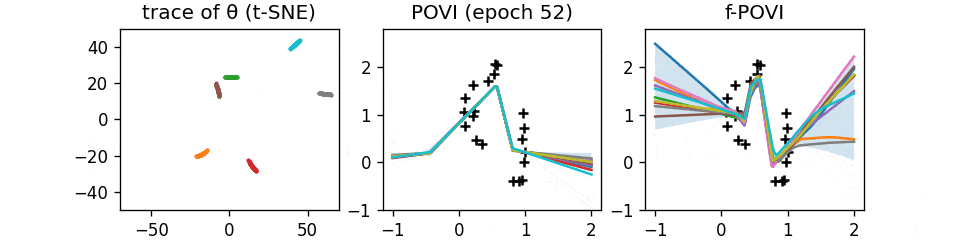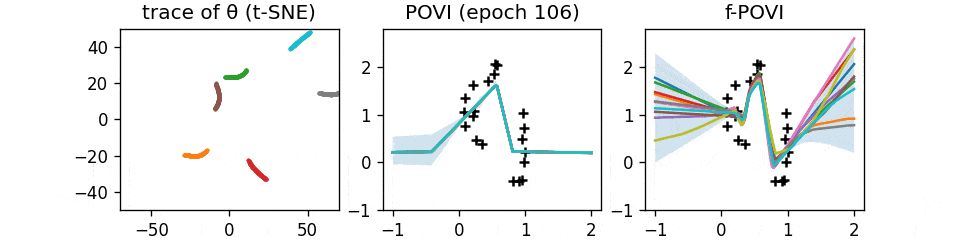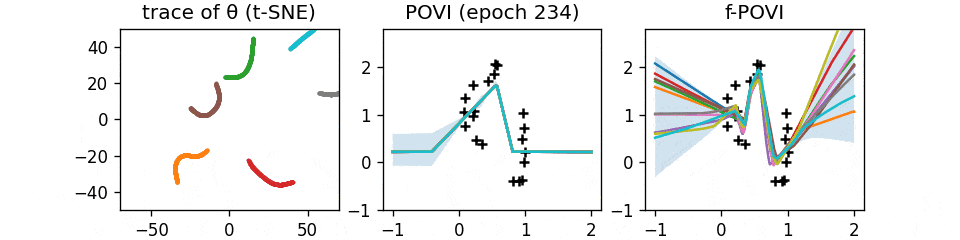
Function Space Particle Optimization for Bayesian Neural Networks.
Ziyu Wang, Tongzheng Ren, Jun Zhu, Bo Zhang.
ICLR 2019.
PDF
Code
Poster
TL;DR
- A curious SVGD/Particle VI-like algorithm, but in function space. GIF.
- The function-space view is important for overparameterized priors like BNNs, because there is a combinatorial number of local maximas in the "weight space", and you can't believe your inference algorithm covers them all.
Too bad we still haven't figured out how to do it properly in the most general case, after all these years.
- But if you can afford to train an ensemble of models, this works well in practice.
Note
- The extensions in arXiv version are only formal calculations obtained by Otto calculus. (This note seems to have been lost during revision.)
- Pretrained weights for the CIFAR-10 experiment can be found here. Please let me know if the weights or the training code doesn't work.
Miscellaneous
Random quotes.
{kind=link}