A variant on this idea which has been suggested many times is to add
`noise' to the training set, randomly perturbing either the feature
vectors ![]() or the classes (or both). Further along this
line, we could model the joint distribution of
or the classes (or both). Further along this
line, we could model the joint distribution of ![]() and create new training sets from this distribution. Bagging can be
seen as the rather extreme form of this procedure in which the model
is the empirical distribution. (Krogh & Vedelsby,1995, use
cross-validation rather than re-sampling, and consider designing
training sets weighted towards areas where the existing classifiers
are prone to disagree.)
and create new training sets from this distribution. Bagging can be
seen as the rather extreme form of this procedure in which the model
is the empirical distribution. (Krogh & Vedelsby,1995, use
cross-validation rather than re-sampling, and consider designing
training sets weighted towards areas where the existing classifiers
are prone to disagree.)
Boosting [Schapire,1990; Freund,1990; Drucker et al.,1993; Drucker et al.,1994; Freund,1995; Freund & Schapire,1995; Freund & Schapire,1996a] is altogether more ambitious. The idea is to design a series of training sets and use a combination of classifiers trained on these sets. (Majority voting and linear combinations have both been used.) The training sets are chosen sequentially, with the weights for each example being modified based on the success of the classifier trained on the previous set. (The weight of the examples which were classified incorrectly is increased relative to those which were classified correctly.) For classifiers that do not accept weights on the examples, resampling with probabilities proportional to the weights can be used.
There have been a number of practical tests of boosting, including Drucker (1996);Drucker & Cortes (1996);Freund & Schapire (1996b);Breiman (1996c) and Quinlan (1996a). Each of Freund & Schapire, Breiman and Quinlan compare bagging and boosting for classification trees (although only Quinlan used weighting rather than weighted re-sampling for boosting), and all find that boosting usually out-performs bagging but can fail so badly as to make the boosted classifier worse that the original.
The original motivation for boosting was to produce a combined classifier that could fit the training set perfectly by concentrating on the regions of the feature space which the current classifier found hard. As both Breiman and Quinlan point out, this is a very different aim from producing a classifier with good generalization in problems with overlapping classes, a problem which requires boosting beyond the point needed to fit the training set perfectly. It seems likely that greater study of boosting will lead to algorithms designed to boost generalization error.
Cesa-Bianchi et al. (1993);Cesa-Bianchi et al. (1996) consider how to learn how to do as well as the best of a class of classifiers over a sequence of examples, and derive bounds for the excess errors made whilst learning which is best. This is a different goal from the usual one in combining classifiers, which is to do better than even the best classifier by exploiting the strengths of all. The algorithm used is boosting-like, maintaining weights for each expert rather than each example.
In (2.50) the factor 1/8 in the exponent can be removed. Parrondo & Van der Broeck (1993) give
![]()
and Vapnik(1995, pp. 66, 85) quotes the constant 4 as in (2.50), although proofs are deferred to the forthcoming Vapnik (1996).
The improvements of Parrondo & Van der Broeck rely on
- [(i)]
- Replacing (2.55) by
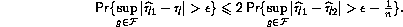
This follows from the binomial inequality
for each choice of sign, and so, conditionally on the first sample
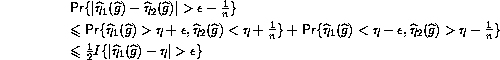
Inequality (1) says that for a binomial distribution the median lies within one of the mean; it seems well-known to combinatorists, none of whom was able to give me a reference.
- replacing the use of Hoeffding's inequality at the top of page 87
by an inequality of Vapnik (1982):
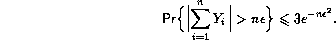
The bound for proposition 2.5 may be improved to
![]() by the same ideas. (The statement in
Parrondo & Van der Broeck,1993, does not follow from their
proof and appears to be wrong.)
by the same ideas. (The statement in
Parrondo & Van der Broeck,1993, does not follow from their
proof and appears to be wrong.)